从数据到智慧 详解大厂知识图谱构建全流程与NLP核心技术
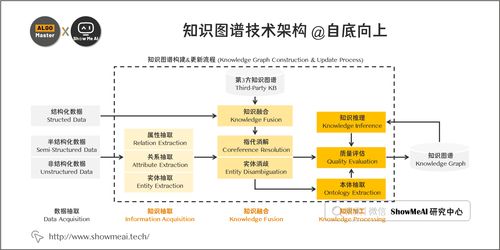
在当今信息爆炸的时代,如何从海量、异构、非结构化的数据中提取出结构化知识,并构建能够理解、推理和应用这些知识的系统,已成为人工智能领域的核心挑战之一。知识图谱(Knowledge Graph)作为一种以图结构形式表示实体、概念及其相互关系的语义网络,正成为各大科技公司(“大厂”)在搜索、推荐、问答、风控等核心业务中不可或缺的底层基础设施。本文将从技术实现视角,深入剖析大厂构建知识图谱的全流程,并重点解析其中涉及的自然语言处理(NLP)与计算机软件及网络技术。
一、知识图谱构建全流程:一个系统化工程
大厂构建知识图谱并非一蹴而就,而是一个融合了数据工程、算法研发和系统工程的复杂闭环流程。其核心阶段通常包括:
1. 知识建模与本体构建:
这是蓝图设计阶段。首先需要定义知识图谱的“骨架”——本体(Ontology)。本体明确了知识图谱中的核心概念(实体类型,如“人物”、“公司”、“产品”)、概念间的层级关系(如“苹果公司”是“科技公司”的子类)、以及实体间的属性与关系(如“创立于”、“是CEO”)。大厂通常会结合业务需求(如电商领域需要“商品”、“品牌”等实体)与行业标准(如Schema.org)来设计本体,确保知识的可扩展性和一致性。
2. 知识获取:多源异构数据融合:
这是“原材料”收集阶段。数据源极其广泛,包括:
- 内部结构化数据:如业务数据库中的用户表、商品表、交易记录。
- 半结构化数据:如网页表格、JSON/XML格式的API数据。
- 非结构化文本数据:如新闻、社交媒体内容、产品描述、客服日志,这是NLP技术的主战场。
* 外部知识库:如维基百科、领域专业数据库。
技术挑战在于数据的清洗、对齐和融合,需要强大的数据管道(Data Pipeline)支持。
3. 知识抽取:NLP技术的核心应用:
这是从非结构化文本中“炼金”的关键步骤,主要依赖NLP技术:
- 命名实体识别(NER):识别文本中属于预定义类别的实体,如人名、地名、组织名、产品名等。大厂通常采用基于深度学习的模型(如BERT、RoBERTa及其变体),并结合领域数据进行微调,以达到极高的准确率和召回率。
- 关系抽取(RE):识别文本中两个实体之间的语义关系,如“马云 创立了 阿里巴巴”中的“创立”关系。方法从早期的模式匹配发展到基于深度学习(序列标注、阅读理解范式)的端到端模型。
- 属性抽取:抽取实体的属性信息,如人物的出生日期、公司的所在地。
- 事件抽取:识别文本中发生的事件、事件的参与角色及时间地点等要素,对理解动态知识尤为重要。
4. 知识融合与对齐:
来自不同数据源的同一实体(如“阿里巴巴”、“Alibaba Group”)可能存在不同表述或冗余信息。此阶段旨在消除歧义、合并冲突、建立统一视图。关键技术包括:
- 实体链接:将文本中提到的实体指称(如“苹果”)链接到知识图谱中唯一的实体ID(是“苹果公司”还是“水果苹果”)。
- 知识消歧:解决同名实体(如“李娜”是歌手还是网球运动员)的歧义问题。
- 数据融合:对不同来源的同一实体的属性值进行冲突检测与择优合并。
5. 知识存储与计算:
经过处理的知识需要被高效存储和查询。图数据库(如Neo4j, JanusGraph, Nebula Graph)因其对图结构数据的原生支持,成为存储知识图谱的热门选择。大厂也常根据规模(如百亿级三元组)和性能需求,自研分布式图存储与计算系统(如阿里巴巴的GraphScope,百度的PGL),结合图计算引擎(如Spark GraphX)进行大规模图分析(如社区发现、影响力传播)。
6. 知识推理与应用:
构建图谱的最终目的是应用。基于已有的知识,可以通过规则推理(如定义“配偶关系的对称性”)或嵌入表示学习(将实体和关系映射到低维向量空间,通过向量运算如TransE进行推理)来发现隐含知识,补全图谱。知识图谱最终赋能上层应用,例如:
- 搜索引擎:提供精准的实体卡片和关联搜索。
- 智能问答:直接回答关于实体的事实性问题。
- 个性化推荐:利用用户、商品、内容间的复杂关系网络进行精准推荐。
- 风险控制:通过企业股权关系、个人社交关系图谱识别欺诈团伙。
二、支撑技术栈:软件与网络技术的融合
一个工业级知识图谱系统的背后,是一套坚实的技术栈:
- 分布式计算与存储:处理海量数据离不开Hadoop、Spark、Flink等大数据框架,以及HBase、Hive等分布式存储系统,确保数据处理的吞吐量和可扩展性。
- 微服务与容器化:知识图谱的构建和更新流程通常被拆分为多个独立的微服务(如NER服务、关系抽取服务、实体链接服务),通过Docker容器化部署,利用Kubernetes进行编排管理,实现敏捷开发和高可用性。
- 流批一体处理:支持离线批量构建全量图谱(批处理)和实时处理流式数据(如新闻流)以增量更新图谱(流处理)。
- 高性能网络与RPC框架:微服务间的高效通信依赖高性能网络基础设施和RPC框架(如gRPC),保证低延迟的数据传输。
- 模型服务化(Model Serving):将训练好的NLP模型(如抽取模型)封装为可扩展的在线服务(常用TensorFlow Serving、TorchServe等),供构建流水线实时调用。
三、挑战与趋势
尽管技术日趋成熟,大厂在构建知识图谱时仍面临诸多挑战:自动化程度仍需提高(减少人工干预)、多模态知识融合(结合图像、视频中的知识)、动态知识更新(实时捕捉世界变化)、以及可解释性与可信赖性。知识图谱将与大规模预训练语言模型(如GPT系列)深度融合,形成“大模型+知识图谱”的双轮驱动,让机器不仅拥有从数据中学习模式的能力,也具备结构化的知识记忆与推理能力,向更通用的人工智能迈进。
知识图谱的构建是一个集NLP、数据工程、图计算、分布式系统于一体的综合性系统工程。大厂通过系统化的流程设计和强大的技术栈,将散落的数据转化为互联的智慧,为智能应用的落地提供了坚实的知识基石。
如若转载,请注明出处:http://www.xuanyunxinxi.com/product/56.html
更新时间:2026-06-19 15:11:37